IT & Engineering
GroupCache: The superior Golang cache
Golang cache makes distributed caching and synchronization simple and easy to deploy with GroupCache. But why is this the superior tool? And what problems does it solve? At Mailgun we have used GroupeCache to reduce latency in our rate-limiting service and reaped the benefits of synchronization, while avoiding deadlock issues when creating and managing unique resources. If you’re not convinced, that’s ok, we’re sure you will be by the end of this.
What is a distributed cache?
A cache is a high-speed memory storage solution that holds high demand data to speed up data access retrieval. A Distributed cache divides the cache into segments and distributes them such that each node in a cluster of servers contains only one segment of the entire cache. In this way, the cache can continue to scale by simply adding new nodes to the cluster.
This is important for a couple of reasons.
- Distributed caches allow the cache to grow as the data grows. They are advantageous in environments with high data volume and load.
- A distributed cache can span multiple servers giving it a much higher transaction capacity.
How does distributed caching work?
Distributed caching systems like Redis and Memcached clients typically work like this:
- The App asks the Client for the cached data via a key.
- Then the Client performs a consistent hash on the key to determine which Node has the data.
- Once the Client has located the data, it makes a network request to the Node.
- The Node returns the data if found.
- The App checks if data is returned, else it renders or fetches the data from the database.
- The App tells Client to store data for this key.
- The Client performs a consistent hash on the key to determine which Node should own the data.
- Finally, the Client stores the data on the Node.
Looking at this flow, there are two big implications that stand out:
- Every cache request results in a round trip to a Node regardless of cache hit or miss.
- You can’t avoid the round trip to a Node by caching the value locally, as the remote Node could invalidate the data at any time without the Apps knowledge.
While neither of these implications are particularly troublesome for most applications, the extra round trips to the database can impact high performance, low latency applications. However, there is one more implication that may not be immediately obvious: the thundering herd!
Solving the thundering herd problem: Cache stampedes and high concurrency
The thundering herd problem is a stampede of requests that overwhelm the system. Sometimes called a cache stampede, dogpiling, or the slashdot effect, this problem happens when concurrent instances of an application all attempt to access data at the same time.
For this discussion, our thundering herd is in response to a cache miss, meaning the data was either removed or never placed in the cache. For example, in normal operation, an application remains responsive under heavy load as long as the data remains cached.
When the cache doesn’t have the data this thundering herd of concurrent work could overwhelm the system and result in congestion, and potential collapse, of the system.
To combat this concurrent work, you need a system to synchronize fetching or rendering of the data. Fortunately, there is a Golang library called GroupCache which can be used to resolve the thundering herd issue and improve on the remote cache implications we mentioned.
What is GroupCache and how does it compare to other caching solutions?
There are many caching solutions on the market. Golang’s GroupCache is an open source solution that differs from popular tools like BigCache, Redis and Memcache, as it integrates directly with your code as an In Code Distributed Cache (ICDC). This means that every instance of the App is a Node in the distributed cache. The advantage? As a full member of the distributed cache, each application instance knows the data structures, not only how to store data for the node, but also how to fetch or render the data if it’s missing.
To understand why this is superior to Redis or Memcached, lets run through the distributed caching flow when using GroupCache. When reading through the flow, keep in mind the GroupCache is a library used by the application that also listens for incoming requests from other instances of the application that are using GroupCache.
- The App asks the GroupCache for the data via a key.
- Next, the GroupCache checks the in memory hot cache for the data, if no data, continue.
- The GroupCache performs a consistent hash on the key to determine which GroupCache instance has the data.
- Then, the GroupCache makes a network request to the GroupCache instance that has the data.
- The GroupCache returns the data if it exists in memory, if not it asks the App to render or fetch data.
- Finally, the GroupCache returns the data to GroupCache instance that initiated the request.
Step 5 is significant in the context of a thundering herd event as only one of the GroupCache instances will perform the render or fetch of the data requested. All other instances of the application – that are also requesting the data from the GroupCache instance –will block until the owning instance of the application successfully renders or fetches the data. This creates a natural synchronization point for data access in the distributed system and negates the thundering herd problem.
Step 2 is also significant as the ability to locally cache the data in memory which avoids the cost of a network round trip, providing a huge performance benefit and reduced network pressure. Since GroupCache is a part of the application, we avoid the possibility of the GroupCache deleting the data without the application’s knowledge, as any such delete event is shared by all instances of the application using GroupCache.
An admittedly minor benefit – but one that those of us who enjoy simplicity can appreciate – is that of deployment. Although it is not overly difficult to deploy and secure Redis and Memcached as separate entities from the application, having a single application to deploy means one less thing for an operator to deal with and keep up to date and secure.
It’s worth mentioning again as it’s easy to overlook. The ability for the cache implementation to render or fetch the data from a database during a cache miss, and the ability to rely on a local in memory hot cache is what makes GroupCache a superior choice among distributed caches. No distributed cache external to your application can provide these benefits.
GroupCache as a synchronization tool
Because GroupCache provides great synchronization semantics, we have found GroupCache to be a superior alternative to distributed or database level locks when creating and managing unique resources.
As an example, our internal analytics engine reads thousands of events and dynamically adds tags with assigned stats. Since we have many instances of the engine running, every new tag seen must be treated as a possible new tag. Normally this would generate a constant stream of upsert requests to our database. By using GroupCache, each instance can query the cache with account:tag key.
If the tag already exists, it’s returned with the latest data on the tag. However, if the tag doesn’t exist, GroupCache relays the request to the owning instance and creates the tag. In this manner, only a single upsert is sent to the database when the system encounters a new tag.
Similarly, we use GroupCache to count unique counters where the system should only record a single instance of a counter. Because we are using Groupcache, we avoid using a distributed lock and deadlock issues completely. This is especially useful when using a nosql database with little to no locking or synchronization semantics of their own.
Using GroupCache
Mailgun runs a modified version of Brad Fitzpatrick’s (patrickmn) original GroupCache library on github.com.
Notable changes to the library are:
- Support for explicit key removal from a group.
Remove() - Support for expired values.
SetBytes(),SetProto()andSetString()now accept an optionaltime.Time{}which represents a time in the future when the value will expire - Support for golang standard
context.Context - Always populates the hotcache
- To use GroupCache, you create a Pool of instances each GroupCache instance will talk to, then you create multiple independent cache Groups which use the same Pool of instances.
- Keep track of peers in our cluster and add our instance to the pool `
http://localhost:8080` pool := groupcache.NewHTTPPoolOpts("http://localhost:8080", &groupcache.HTTPPoolOptions{}) - Add more peers
pool.Set("http://peer1:8080", "http://peer2:8080") - Create a new group cache with a max cache size of 3MB group: =
groupcache.NewGroup("users", 3000000, groupcache.GetterFunc( func(ctx context.Context, id string, dest groupcache.Sink) error { // Returns a protobuf struct `User` if user, err := fetchUserFromMongo(ctx, id); err != nil { return err } - Set the user in the groupcache to expire after 5 minutes
if err := dest.SetProto(&user, time.Now().Add(time.Minute*5)); err != nil { return err } return nil }, )) - var user User
- Fetch the definition from the group cache ctx,
cancel := context.WithTimeout(context.Background(), time.Second*10) if err := group.Get(ctx, “key”, groupcache.ProtoSink(&user)); err != nil { return nil, err } cancel()
How to implement with HTTP/2 and TLS
GroupCache uses HTTP to communicate between instances in the cluster. If your application also uses HTTP, GroupCache can use the same HTTP port as your application. Simply add the pool as a handler with it’s own path.
1// Our application2http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {3 fmt.Fprint(w, "Hi there")4})5// Handle GroupCache requests6http.Handle("/_groupcache/", pool)7log.Fatal(http.ListenAndServe(":8080", nil))8
If your application has TLS configured, GroupCache will benefit from the same TLS config your application uses, additionally having the option of enabling HTTP/2 which further improves performance of GroupCache requests. You can also use HTTP/2 without TLS via H2C.
Mailgun’s key removal update
A notable difference to the Mailgun version of GroupCache is the ability to explicitly delete keys from the cache. When an instance wants to remove a key, it first deletes the key from the owning instance and then sends the delete requests to all other instances in the pool. This ensures any future requests from non-owner instances in the pool to the owner will result in a new fetch or render of the data (or an error if the data is no longer available.)
As with any distributed system, there is the possibility that an instance is not available, or connectivity has been lost when the remove request was made. In this scenario group.Remove() will return an error indicating that some instances were not contacted and the nature of the error.
Depending on the use case, the user then has the option of retrying the group.Remove() call or ignoring the error. For some systems, ignoring the error might be acceptable especially if you are using the expired values feature.
The expire values feature allows you to provide an optional expiration time time.Time which specifies a future time when the data should expire.
1// Our application2http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {3 fmt.Fprint(w, "Hi there")4})5// Handle GroupCache requests6http.Handle("/_groupcache/", pool)7log.Fatal(http.ListenAndServe(":8080", nil))8
In the scenario above where we temporarily lose connectivity to an instance, we say that the pool of instances is in an inconsistent state. However, when used in conjunction with the data expiration feature we know the system will eventually become consistent again when the data on the disconnected instances expires.
There are other much more complex solutions to solving this problem but we have found in practice eventually consistent solutions are the simplest and least error prone way to deal with network disruptions.
Mailgun’s performance improvements using GroupCache
At Mailgun, our first production use of GroupCache was in our ratelimit service. Since this service must operate at a very high performance/low latency level, traditional caching systems were a concern, the more round trips we introduced to the request pipeline the more opportunities we had to introduce additional latency.
The following graphs show the total number of cache hits and of those hits the total number of hits that resulted in a roundtrip to another GroupCache instance. This demonstrates exactly how much we benefit from the local in memory hot cache as opposed to making a roundtrip call on every request.
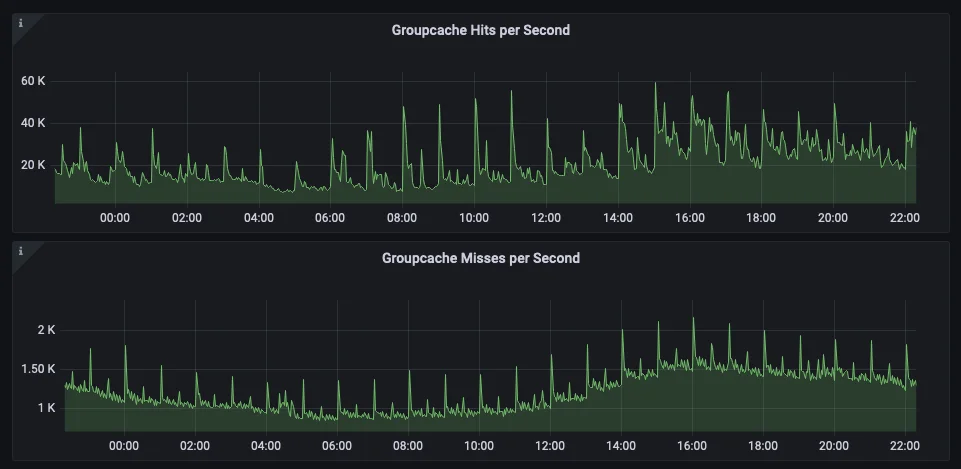
You can see in the next graph exactly how much MongoDB and our application benefits from the thundering herd avoidance as new keys are retrieved from the system.
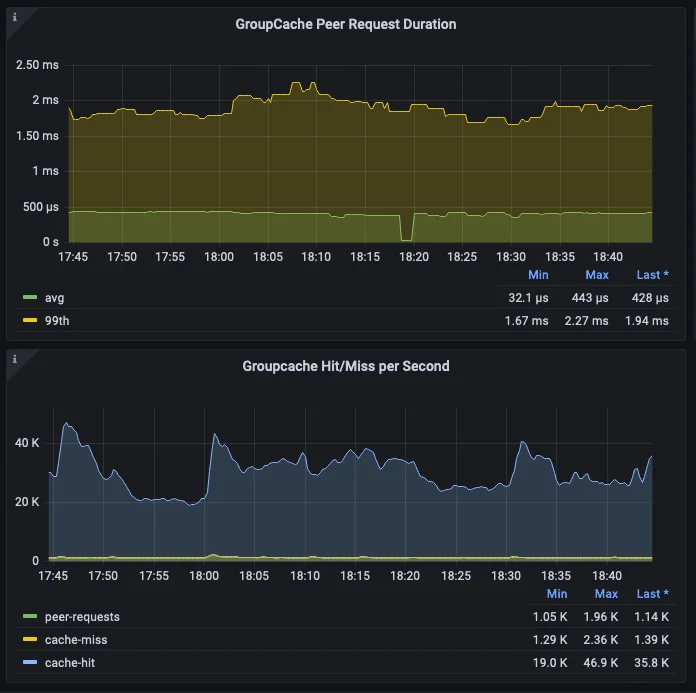
The actual calls to MongoDB are a small fraction of the total requests actually made to the service. This, in addition to the speed of gubernator, is what allows our ratelimit service to perform at low latency even during high load.
Here you can see the rate limits service response time metrics. Keep in mind for each request we make a gubernator call and a GroupCache request which may or may not result in a GroupCache http request or MongoDB request. (This graph shows the slowest of the responses, not the average).
Conclusion: Distributed caching made easy
GroupCache has improved performance for our services at Mailgun. It makes distributed caching and synchronization simple and easy to deploy. My hope is that others will discover the same benefits that we are enjoying and inspire other ICDC implementations in other languages.
Was this helpful? At Mailgun we are constantly evaluating and implementing new ways to help scale our services and improve our performance. This isn’t always easy. We’d love for you to learn from our experiences. Subscribe to our newsletter for more content like this.
