IT & Engineering
Gubernator: Cloud-native distributed rate limiting for microservices
Today, Mailgun is excited to opensource Gubernator, a high performance distributed rate-limiting microservice. What does Gubernator do? Great question:
Features of Gubernator
- Gubernator evenly distributes rate limit requests across the entire cluster, which means you can scale the system by simply adding more nodes.
- Gubernator doesn’t rely on external caches like Memcache or Redis, as such there is no deployment synchronization with a dependant service. This makes dynamically growing or shrinking the cluster in an orchestration system like kubernetes or nomad trivial.
- Gubernator holds no state on disk, It’s configuration is passed to it by the client on a per-request basis.
- Gubernator provides both GRPC and HTTP access to its API.
- Can be run as a sidecar to services that need rate-limiting or as a separate service.
- Can be used as a library to implement a domain-specific rate-limiting service.
- Supports optional eventually consistent rate limit distribution for extremely high throughput environments.
- Gubernator is the english pronunciation of governor in Russian, also it sounds cool.
Now, we’re sure you have a lot of questions as to why we decided to opensource Gubernator. So before we get into how Gubernator works, let’s answer a few of those questions first. The biggest one you’re asking is probably…
Why not use Redis?
A few things jumped out at us while evaluating Redis.
- Using the basic Redis rate limit implementation would incur additional network round trips even with pipelining.
- We could reduce the round trips by using https://redis.io/commands/eval and writing a LUA script which we would need to maintain for each algorithm we implement.
- Every single request would result in at least 1 round trip to Redis. Combined that with at least 1 round trip to our microservice this means at least 2 round trips per request to our service.
The optimal solution for Redis is to write a LUA script which implements the rate limit algorithm. That script is then stored on the Redis server and is called for each rate limit request. In this scenario, most of the work is done by Redis and our microservice is basically a proxy for accessing Redis. This being the case, we have two options:
- Create Gubernator as a rate limit library that provides access to Redis. This library would be used by every service which needs rate limiting.
- Eliminate Redis and implement the distributing, caching, and limiting algorithms in a rate-limiting microservice with a thin GRPC client to be used by each service.
Why a microservice?
Mailgun is a polyglot company with python and golang making up the majority of our codebase. If we choose to implement rate-limiting as a library, this requires a minimum of a python and a golang version of the library. We have gone this route before internally with a python and golang version of the same library. In our experience, shared libraries across services have the following downsides.
- Bug and feature updates to the library can entail, at best, an update to the dependency. At worst, it requires making modifications to all services that use the library in all languages supported.
- Rarely do developers want to maintain or write new features in both languages. This usually results in one version of the library having more features or being better maintained than the other.
As the number of microservices and languages in our ecosystem continues to grow, these problems compound and get worse. In comparison, GRPC and HTTP libraries are easily created and maintained for every language which needs access to Gubernator.
For microservices, bug updates and new features can be added with no disruption to dependent services. As long as API breaking changes are not allowed, dependent services can opt into new features without needing to update all dependent services.
The killer feature for Gubernator as a microservice is that it creates a synchronization point for the many requests that enter the system. Requests received within a few microseconds of each other can be optimized and coordinated into batches which reduces the overall bandwidth and round trip latency the service uses under heavy load. Several services all running on a single host all with the same library running in their own respective processes do not have this capability.
Why is Gubernator stateless?
Gubernator is stateless in that it doesn’t require disk space to operate. No configuration or cache data is ever synced to disk, and that’s because every request to Gubernator includes the config for the rate limit.
At first, you might think this an unnecessary overhead to each request. However, in reality, a rate limit config is made up of only 4 64-bit integers. The configuration is made up of the Limit, Duration, Algorithm, and Behavior (See below for details on how this works). It is because of this simple configuration that Gubernator can be used to provide a wide variety of rate limit use cases which clients can employ. A few of these use cases are:
- Ingress limiting – Typical HTTP based 402 Too Many Requests type limiting
- Traffic Shedding – Deny only new or unauthenticated requests when your API is in a bad state.
- Egress limiting – Blasting external SMTP servers with millions of messages is No Bueno.
- Queue Processing – Know when a request can be handled immediately or should be queued and processed in the order it was received.
- API Capacity Management – Place global limits on the total number of requests a collective API system can handle. Deny or Queue requests that breach the normal operating capacity of the system.
In addition to the aforementioned use cases, a configuration-less design has major implications for microservice design and deployment:
- No configuration synchronization on deployment. When a service that uses Gubernator is deployed, there is no rate limit config that needs to be pre-deployed to Gubernator.
- Services that use Gubernator own their rate limit domain model for their problem space. This keeps domain-specific knowledge out of Gubernator, so Gubernator can focus on what it does best — rate limiting!
Outside of those questions, let’s talk more about Gubernator as a whole, starting with how it works.
How Gubernator works
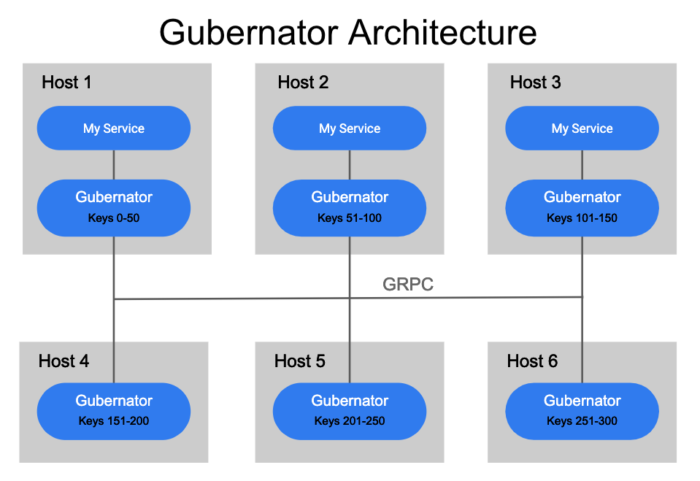
Gubernator is designed to run as a distributed cluster of peers which utilize an in-memory cache of all the currently active rate limits, as such no data is ever synced to disk. Since most network-based rate limit durations are held for only a few seconds, losing the in-memory cache during a reboot or scheduled downtime isn’t a huge deal. For Gubernator, we choose performance over accuracy as it’s acceptable for a small subset of traffic to over request for a short period of time (usually seconds) in the case of cache loss.
When a rate limit request is made to Gubernator, the request is keyed and a consistent hashing algorithm is applied to determine which of the peers will be the owner of the rate limit request. Choosing a single owner for a rate limit makes atomic increments of counts very fast and avoids the complexity and latency involved in distributing counts consistently across a cluster of peers.
Although simple and performant, this design could be susceptible to a thundering herd of requests since a single coordinator is responsible for possibly hundreds of thousands of requests to a rate limit.
To combat this, clients can request `Behaviour=BATCHING` which allows peers to take multiple requests within a specified window (default is 500 microseconds) and batch the requests into a single peer request, thus reducing the total number of over the wire requests to a single Gubernator peer tremendously.
In order to ensure each peer in the cluster accurately calculates the correct hash for a rate limit key, the list of peers in the cluster must be distributed to each peer in the cluster in a timely and consistent manner. Currently, Gubernator supports using etcd or the kubernetes endpoints API to discover Gubernator peers.
Gubernator operation
When a client or service makes a request to Gubernator, the rate limit config is provided with each request by the client. The rate limit configuration is then stored with the current rate limit status in the local cache of the rate limit owner. Rate limits and their configuration that are stored in the local cache will only exist for the specified duration of the rate limit configuration.
After the duration time has expired and if the rate limit was not requested again within the duration, it is dropped from the cache. Subsequent requests for the same name and unique_key pair will recreate the config and rate limit in the cache and the cycle will repeat. On the other hand, subsequent requests with different configs will overwrite the previous config and will apply the new config immediately.
An example rate limit request sent via GRPC might look like the following:
rate_limits:rn # Scopes the request to a specific rate limit rn - name: requests_per_secrn # A unique_key that identifies this rate limit requestrn unique_key: account_id=123|source_ip=172.0.0.1rn # The number of hits we are requestingrn hits: 1rn # The total number of requests allowed for this rate limitrn limit: 100rn # The duration of the rate limit in millisecondsrn duration: 1000rn # The algorithm used to calculate the rate limit rn # 0 = Token Bucketrn # 1 = Leaky Bucketrn algorithm: 0rn # The behavior of the rate limit in gubernator.rn # 0 = BATCHING (Enables batching of requests to peers)rn # 1 = NO_BATCHING (Disables batching)rn # 2 = GLOBAL (Enable global caching for this rate limit)rn behavior: 0
An example response would be:
rate_limits:rn # The status of the rate limit. OK = 0, OVER_LIMIT = 1rn - status: 0,rn # The current configured limitrn limit: 10,rn # The number of requests remainingrn remaining: 7,rn # A unix timestamp in milliseconds of when the rate limit will reset,rn # or if OVER_LIMIT is set it is the time at which the rate limitrn # will no longer return OVER_LIMIT.rn reset_time: 1551309219226,rn # Additional metadata about the request the client might find usefulrn metadata:rn # This is the name of the node that owns this requestrn "owner": "api-n03.staging.us-east-1.mailgun.org:9041"
Global behavior
Since Gubernator rate limits are hashed and handled by a single peer in the cluster, rate limits that apply to every request in a data center would result in the rate limit request being handled by a single peer for the entirety of the data center.
For example, consider a rate limit with name=requests_per_datacenter and a unique_id=us-east-1. Now imagine that a request is made to Gubernator with this rate limit for every HTTP request that enters the us-east-1 data center. This could be hundreds of thousands, or even potentially millions of requests per second that are all hashed and handled by a single peer in the cluster. Because of this potential scaling issue, Gubernator introduces a configurable behavior called GLOBAL.
When a rate limit is configured with behavior=GLOBAL, the rate limit request that is received from a client will not be forwarded to the owning peer. Instead, it will be answered from an internal cache handled by the peer who received the request. Hits toward the rate limit will be batched by the receiving peer and sent asynchronously to the owning peer where the hits will be totaled and the OVER_LIMIT calculated. It is then the responsibility of the owning peer to update each peer in the cluster with the current status of the rate limit, such that peer internal caches routinely get updated with the most current rate limit status from the owner.
Side effects of global behavior
Since Hits are batched and forwarded to the owning peer asynchronously, the immediate response to the client will not include the most accurate remaining counts. That count will only get updated after the async call to the owner peer is complete and the owning peer has had time to update all the peers in the cluster. As a result, the use of GLOBAL allows for greater scale but at the cost of consistency. Using GLOBAL can increase the amount of traffic per rate limit request if the cluster is large enough. GLOBAL should only be used for extremely high volume rate limits that don’t scale well with the traditional non GLOBAL behavior.
Gubernator performance
In our production environment, for every request to our API we send 2 rate-limit requests to Gubernator for rate limit evaluation; one to rate the HTTP request, and the other to rate the number of recipients a user can send an email too within the specific duration. Under this setup, a single Gubernator node fields over 2,000 requests a second with most batched responses returned in under 1 millisecond.
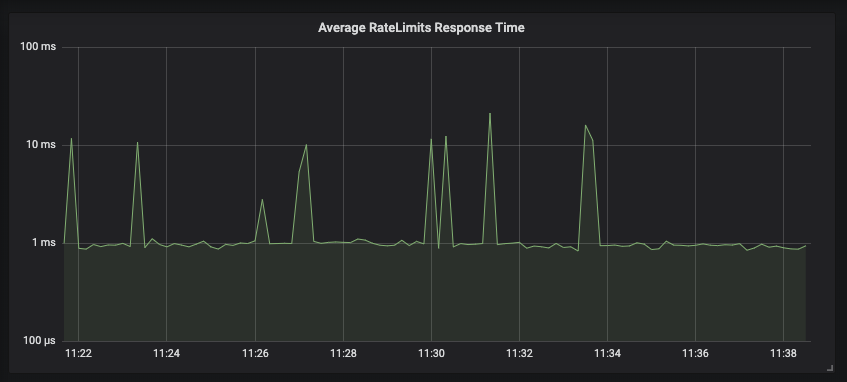
Peer requests forwarded to owning nodes typically respond in under 30 microseconds.
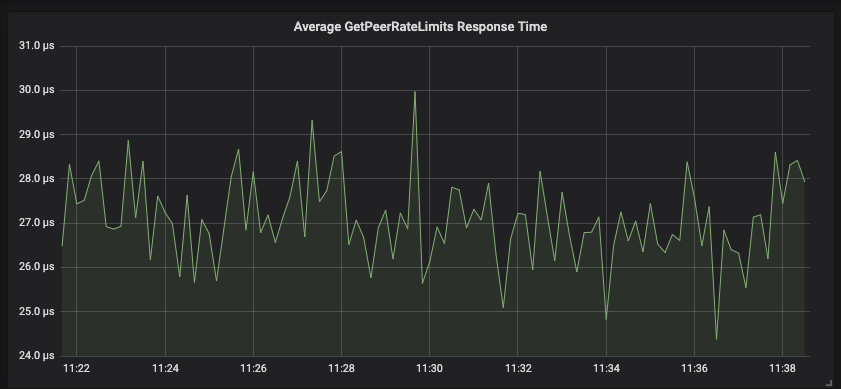
Since many of our public-facing APIs are written in python, we run many python interpreter instances on a single node. Those python instances will forward requests locally to the Gubernator instance which then batches and forwards requests to owning nodes.
Gubernator allows users to choose non-batching behavior which would further reduce latency for client rate limit requests. However, because of throughput requirements, our production environment uses Behaviour=BATCHING with the default 500-microsecond window. In production, we have observed batch sizes of 1,000 during peak API usage. Other users who don’t have the same high traffic demands could disable batching and would see lower latencies but at the cost of throughput.
Gubernator as a library
If you are using Golang, you can use Gubernator as a library. This is useful if you wish to implement a rate limit service with your own company-specific model on top. We do this internally here at Mailgun with a service we creatively called ratelimits, which keeps track of the limits imposed on a per-account basis. In this way, you can utilize the power and speed of Gubernator but still layer business logic and integrate domain-specific problems into your rate limiting service.
When you use the library, your service becomes a full member of the cluster participating in the same consistent hashing and caching as a stand-alone Gubernator server would. All you need to do is provide the GRPC server instance and tell Gubernator where the peers in your cluster are located.
Conclusion
Using Gubernator as a general-purpose rate limiting service allows us to rely on microservice architecture without compromising on service independence and duplication of work required by common rate-limiting solutions. We hope by open-sourcing this project others can collaborate on and benefit from the work we began here.
Interested in working at Mailgun? We’re hiring! And there are several dev positions available. Check out our current openings here.
