Deliverability
How to prevent outbound spam
Did you know malicious actors can use your network to send spam? Discover what outbound email is and how machine learning can help you prevent it.
Deliverability
Spam sucks. That’s the long and short of it.
We’ve talked about how to identify and prevent spam, but what if you’re part of the problem?
We’re talking about outbound spam exiting your email server. In this article, we’ll go over what outbound spam is and how to fight outbound spam. Then, we’ll dive into our machine learning tutorial on how to detect and prevent outbound spam.
Outbound spam is exactly what it sounds like: spam that exits your network and lands in the inbox of unsuspecting customers or subscribers. This happens when spammers infiltrate your network and exploit it to send spam.
Email service providers (ESPs) like Mailgun and businesses like you need to watch out for outbound messages considered spam because it can destroy your IP reputation and lead to IP blocklisting. This means that a recipient’s internet service provider (ISP) has detected spammy behavior and has decided to block all messages, legitimate or not, that originate from your IP address.
This is terrible news for your email programs or marketing campaigns. After all, you need emails to land in your subscriber’s inbox so they can open your messages and engage with your brand.
Fighting outbound spam takes constant vigilance. For instance, you can use outbound spam filters. These filters installed in your own network can be configured to identify individual senders based on authentication protocols. This way, you can track who is sending emails on your network and identify spam-like behavior.
Spam identification and prevention techniques usually rely on vigilant email users or third-party software. However, spam sometimes slips through the cracks because it’s disguised. Spam doesn’t always look like spam.
Sometimes scammers pretend to be legitimate online retailers by using a fake website or a fake ad on a real shopping site. In these cases, both the email messages and embedded links will look legitimate even though they belong in your junk folder.
How can we make spam detection better? At Mailgun, we believe in using machine learning to power everyday tasks, such as parsing HTML quotations.
Below, we’ll walk through how you can apply machine learning to build a model to detect spam. We’ll start by building a dataset. Then, we’ll try to fit different models to the data. Lastly, we’ll validate our model. We used R for our analysis, but you can use another tool like scikit-learn, Weka, or MOA.
First, let’s take a look at how spammers behave. We’ll use their behavioral pattern to build a model to identify when our outgoing mail appears like spammy behavior.
To differentiate between spam that looks legitimate and actually legitimate messages, we focused on the speed with which spammers send a particular amount of spam.
We classified over 1000 email accounts and collected the following data:
Here is a sample entry from our dataset:
timepassed,time2send,class rn252202,961501,legitimate rn391006,11291,spam rn...
It’s just a CSV file.
For the analysis, I was using R but depending on your task and personal preferences you might use something else – scikit-learn, Weka, MOA, etc.
Two-thirds of the dataset were reserved for training and one third for validation:
x u003c- read.csv(file=u0022firstXmessages.csvu0022, sep=u0022,u0022, head=TRUE)rnrn## pick rows classified as spamrnspam u003c- x[x$class %in% c(u0022spamu0022), ]rnrn## shuffle the data pointsrntotalspam u003c- nrow(spam) rnspam u003c- spam[sample(totalspam), ]rnrn## keep 1 / 3 for validation and 2 / 3 for trainingrnvalidatespamrows u003c- totalspam / 3 rnvalidatespam u003c- spam[sequence(validatespamrows), ] rntrainspam u003c- spam[validatespamrows + sequence(totalspam - validatespamrows), ]rnrn## repeat for legitimate domainsrnlegit u003c- x[x$class == u0022legitimateu0022, ] rntotallegit u003c- nrow(legit) rnlegit u003c- legit[sample(totallegit), ] rnvalidatelegitrows u003c- totallegit / 3 rnvalidatelegit u003c- legit[sequence(validatelegitrows), ] rntrainlegit u003c- legit[validatelegitrows + sequence(totallegit - validatelegitrows), ]rnrn## merge legitimate and spam datapoints together and shufflerntrain u003c- rbind(trainspam, trainlegit) rntrain u003c- train[sample(nrow(train)), ]rnrnvalidate u003c- rbind(validatespam, validatelegit) rnvalidate u003c- validate[sample(nrow(validate)), ] rnvalidatex u003c- subset(validate, select=-class)
Now, we’re ready to model our data.
After building our dataset, we tried out different models for classification analysis. Classification analysis identifies and assigns categories to a data collection to allow for more accurate analysis. In this case, we’re trying to identify spam and legitimate emails.
First, we tried the Support Vector Machines (SVM) model with a linear kernel that transforms data in a linear form. The visualization plot below gives you a good understanding of the data points distribution:
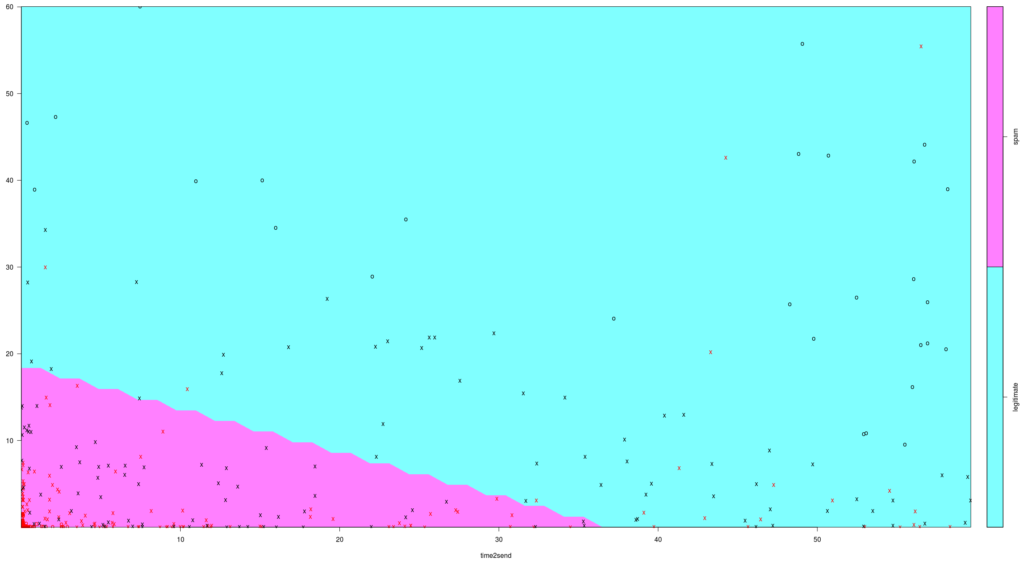
The X-axis is “time to send” and the Y-axis is “time lapsed before sending”. Red marks indicate spam email data points, and black marks indicate legitimate email data points. From this chart, it seems that spammers start sending sooner and send faster.
However, this model didn’t pass validation. We’ll talk more about validation in the next section. For now, let’s talk about the second model we tried: Classification And Regression Tree (CART).
library(rpart)rnrn## grow tree rnfit u003c- rpart(train$class ~., method=u0022classu0022, data=train)rnrn## plot tree rnplot(fit, uniform=TRUE, rn main=u0022Classification Tree for how fast spammers sendu0022)rntext(fit, use.n=TRUE, all=TRUE, cex=.8)

This looks promising. When each stated condition is true, we move to the left branch. As you can see, as time2send increases, so do the fraction of legitimate emails. The opposite is true for spam emails, similar to what we saw in the SVM model above.
Let’s validate our model in the next section below.
We want to assess our model using Precision and Recall performance metrics.
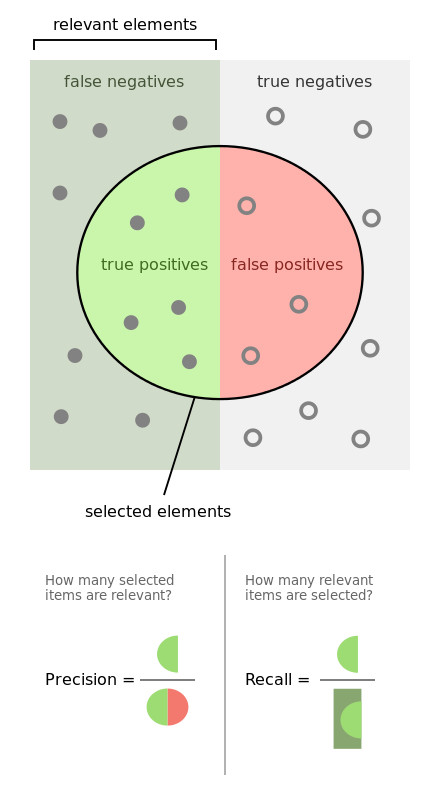
Precision and Recall explainer (source)
“Precision” refers to the fraction of relevant instances among the retrieved instances. This means we can determine how high Spam Precision is based on the fraction of spam accounts among all the accounts retrieved by our model.
“Recall” refers to the fraction of relevant instances that were retrieved. We can determine how high Spam Recall is based on the fraction of spam instances retrieved.
To create a good spam filter, we can allow the occasional spam message, but we should not prevent any legitimate emails from being delivered. We want to focus on the following metrics for our model to ensure we can accurately distinguish between spam and legitimate emails:
Below are the Precision and Recall metrics for our first SVM linear model:
y u003c- predict(fit, validatex, type=u0022classu0022) rnconfusionmatrix u003c- table(validate$class, y) rnprint(Evaluate(cm=confusionmatrix))rnrnClass Precision Recall rnlegitimate 0.7031250 0.6000000 rnspam 0.8814229 0.9214876
As you can see, we only have 60% Legitimate Recall. This is far too low.
Let’s see the validation for our second CART model:
Class Precision Recall rnlegitimate 0.8333333 0.6666667 rnspam 0.9027237 0.9586777 rn
The metrics look better, but Legitimate Recall still isn’t very high.
As a final step, we decided to see how our CART model fits into an SVM visualization chart, as shown below:
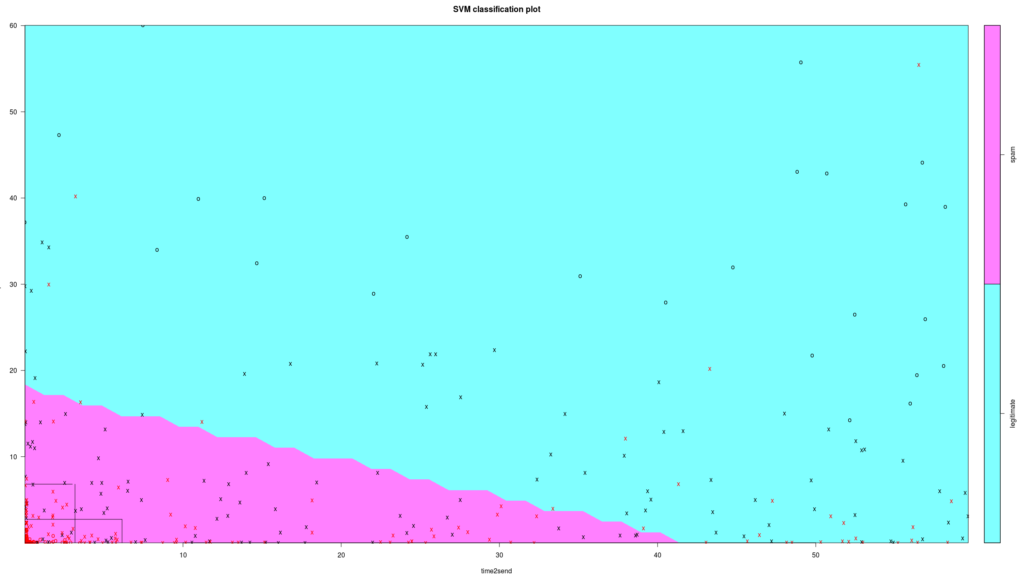
The data points in emerged quadrants are pretty much all spam. This is what we needed: a simple model that would make sense and catch only spammers.
This model is a rough first step to using machine learning to catch spam. The next step would be to add more features to our dataset. We encourage you to incorporate machine learning into your everyday tasks, like in this walkthrough.
We’ve given you some tips on how to stop your outbound emails from being outbound spam. We’ve also included a machine learning to model spam detection for advanced users as a bonus.
On the other side of the spam equation and finding that your Mailgun email campaigns get lost in your subscribers’ spam folders? Check out our blog post about staying on the good side of email providers.
