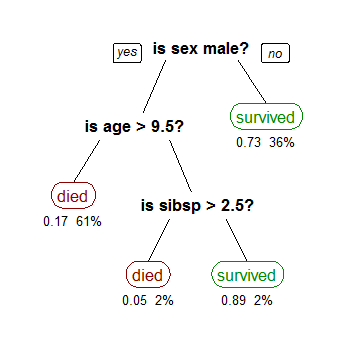Avoiding the blind spots of missing data with machine learning
You have a project, and you want to apply machine learning to it. You start simple: add one feature, collect data, create a model. You add another feature that’s really useful, but it’s only represented in half of your data points. You want to be smart and use all the data you have (including the one with missing values), but how do you do that?
You have a project, and you want to apply machine learning to it. You start simple: add one feature, collect data, create a model. You add another feature that’s really useful, but it’s only represented in half of your data points. You want to be smart and use all the data you have (including the one with missing values), but how do you do that?
As a developer, when I run into a problem, I try to google a solution that works. It doesn’t have to be 100% mathematically accurate, but it should make sense. My search led me to Missing Value in Data Analysis on Stack Overflow.
Solutions vary from something as simple as filling gaps with mean or most popular values to predicting missing values first. In my case, I introduced a separate binary feature indicating if the value is missing.
Whenever I doubted a solution, I turned to math. Math is very precise about when something does or does not work, and what the conditions and the trade-offs are. There’s also a lot written about data imputation– people get doctoral degrees working on this problem!
But then I came across a different approach (kind of by accident). Instead of trying to impute the data, you can use algorithms that don’t require the data to be imputed. They just work out of the box – missing values or not. Sounds like a fairy tale, right?
When I was doing my research, nobody mentioned anything like this to me. I talked to PhDs and people working in the field, and all I heard back was data imputation.
Then I ran into a Coursera course that went into great detail about decision tree algorithms. The way decision trees work, you start at the root and go left or right with a certain probability. Here’s a decision tree for the survival of passengers on the Titanic:
The way decision tree algorithms like C4.5, C5.0, and CART account for missing values goes like this:
Imagine that a feature value is unknown, which means you can’t check the condition and have no way of knowing which branch to follow. One popular approach is to use the most common value. This is essentially the equivalent of picking the most probable branch.
What tree algorithms do is consider both branches with weights equal to the probability of the branches.
Learning by example
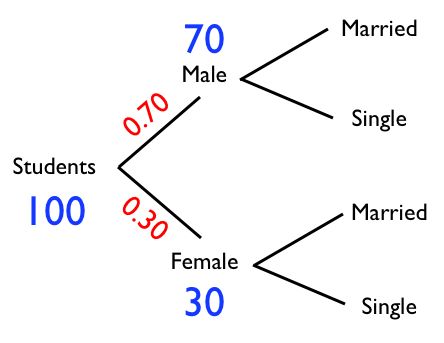
Let’s pull in another example. Here’s a probability tree from a simple GMAT test that assumes a sample size of 100 students in a college class:
If you’re male, the probability that you’re single is
50 / 70 = 71%
If you’re female, the probability of being single is
20 / 30 = 67%
If the gender is unknown, the probability of being single is
(0.7 71%) + (0.3 67%) = 70%
0.7 because 70 students out of 100 are male. 0.3 because 30 students out of 100 are females.
By breaking down the overall probability into branch probabilities with weights, we consider all possibilities. In general, I think this is a much better way to overcome missing data and teach our model to generalize future values.
Unfortunately, libraries that implement these algorithms rarely support missing values. For example, scikit-learn library – the de facto machine learning library for Python – requires all values to be numeric.
But there are still good libraries such as Orange that do support missing values. And as it turns out, the limitation can be overcome.
The power of data imputation
At first, this lack of support for missing values made me feel angry and amused. I mean, seriously, why can’t the very algorithm whose advantage is a built-in support for missing values be used without data imputation?! Come on!
And the beauty of data imputation is that it can be applied to any machine learning algorithm, not just decision trees.
That just blew my mind! An obstacle became a solution, all thanks to the same simple idea!
Lessons Learned
No matter what field you’re working in or how good you are at collecting data, missing values are gonna come up. Maybe you’re working on a credit scoring application. Or maybe you’re trying to predict when email recipients are most likely to open their messages, so you can schedule accordingly. Real tasks tend to have gaps.
There are so many different ways to think about a problem like missing values, and depending on your case, the answers can be different. But in the heart of a complex solution often lies a simple idea.
Most people would agree cookies make life better. For us, they help us make our site and marketing better. But if you don’t like cookies, that’s cool – you can let us know by clicking the settings button!
Your Cookie Choices
When you visit any web site, it may store or retrieve information on your browser, mostly in the form of cookies. This information might be about you, your preferences or your device and is mostly used to make the site work as you expect it to. The information does not usually directly identify you, but it can give you a more personalised web experience. Because we respect your right to privacy, you can choose not to allow some types of cookies. Click on the different category headings to find out more and change our default settings. However, blocking some types of cookies may impact your experience of the site and the services we are able to offer. Cookie Statement
These cookies are necessary for the website to function and cannot be switched off in our systems. They are usually only set in response to actions made by you which amount to a request for services, such as setting your privacy preferences, logging in or filling in forms. You can set your browser to block or alert you about these cookies, but some parts of the site will not then work. These cookies do not store any personally identifiable information.
Cookie details
These cookies allow us to count visits and traffic sources so we can measure and improve the performance of our site. They help us to know which pages are the most and least popular and see how visitors move around the site. All information these cookies collect is aggregated and therefore anonymous. If you do not allow these cookies we will not know when you have visited our site, and will not be able to monitor its performance.
Cookie details
These cookies enable the website to provide enhanced functionality and personalisation. They may be set by us or by third party providers whose services we have added to our pages. If you do not allow these cookies then some or all of these services may not function properly.
Cookie details
These cookies may be set through our site by our advertising partners. They may be used by those companies to build a profile of your interests and show you relevant adverts on other sites. They do not store directly personal information, but are based on uniquely identifying your browser and internet device. If you do not allow these cookies, you will experience less targeted advertising.
Cookie details
These cookies are set by a range of social media services that we have added to the site to enable you to share our content with your friends and networks. They are capable of tracking your browser across other sites and building up a profile of your interests. This may impact the content and messages you see on other websites you visit. If you do not allow these cookies you may not be able to use or see these sharing tools.
Cookie details