Product
Open sourcing our email signature parsing library
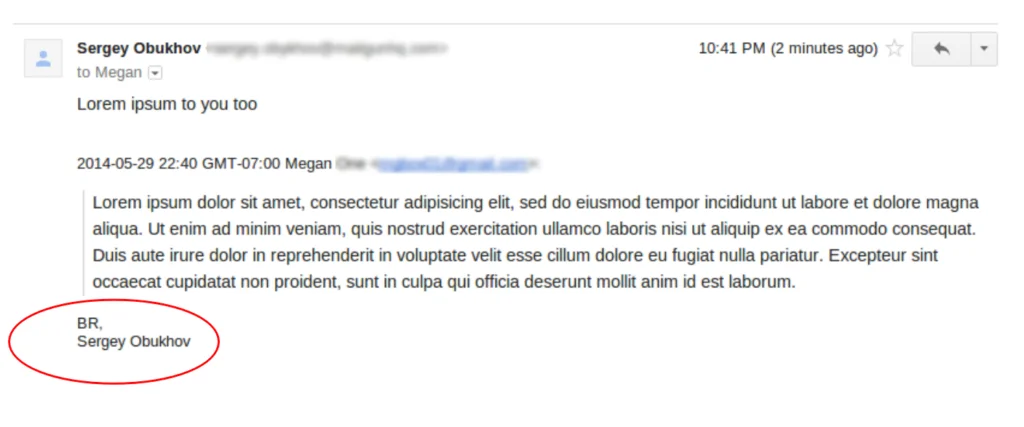
Back in 2011, we had several customers ask us for a high level message parsing API that they could use to strip signatures and quotes from an email like you see below:
The problem
While simple for humans, this is actually quite a challenging task for machines. One of the main reasons is because there is no standard format for an email message. Different email clients compose replies in different manners and even within the same email client, the sender can change the format to whatever they choose. For example, users can place their reply after quoting the original message (bottom-posting):
At 10.01am Wednesday, Danny wrote:
> By the way, which systems will be updated? I had some network
> problems after last week's update. Will I have to reboot?
No, you won't have to reboot.
before the quoted original message (top-posting):
No, you won't have to reboot.
-------- Original Message --------
From: Danny
Sent: Tuesday, October 16, 2007 10:01 AM
To: Jim
Subject: RE: Job
By the way, which systems will be updated? I had some network
problems after last week's update. Will I have to reboot?
or even interleave their reply:
> Can you present your report an hour later?
Yes I can. The summary will be sent no later than 5pm.
Jim
At 10.01am Wednesday, Danny wrote:
>> 2.00pm: Present report
> Jim, I have a meeting at that time. Can you present your report an hour later?
In fact, there are so many different ways to reply, there is even a Wikipedia article about it! All of this makes parsing the body of an email a challenging task.
Even with machine learning, we had to constantly adjust things. Email formatting is constantly changing, phone email clients are introducing new signatures like “Sent from your XXX phone”, new edge cases are discovered, etc.
Here is a simple example. Back in the day, all email signatures were separated with dashes:

So the first thing that comes to mind is to write a regex to detect dashes as a signature splitter and extract lines after it as a signature:
>>> signature = regex.match("^[s]*--*[s]*[a-z .]*$).*", message)
But the next thing you know you get an email like this:
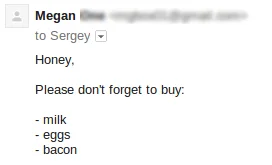
And your parser strips off the most important part of the email. It’s a very simple example and you could easily work around it. But in real life, things get much more complicated and tricky.
Our Solution
We did a lot of research, looked at all the variations of email that passes through Mailgun and came up with a solution based on some machine learning techniques. The solution has been in production for several years now, undergoing bug fixes and enhancements. Overall we have received positive feedback from customers, though naturally, developers tend to point out where you could improve.
So now you all have the chance to help improve the solution. Because of the constantly changing and distributed landscape of email, we’ve decided to tackle this problem with a distributed solution: we’re open sourcing our library so we can hack on this together!
We’re calling our new library talon after a multipurpose robot designed to perform missions ranging from reconnaissance to combat and operate in a number of hostile environments.
In case you want to start testing it right away, we’ve prepared a simple Demo app and a QuickStart Guide for you. Otherwise read on for a more general overview, approaches we took, and assessment results.
Here’s how most common workflows look like:
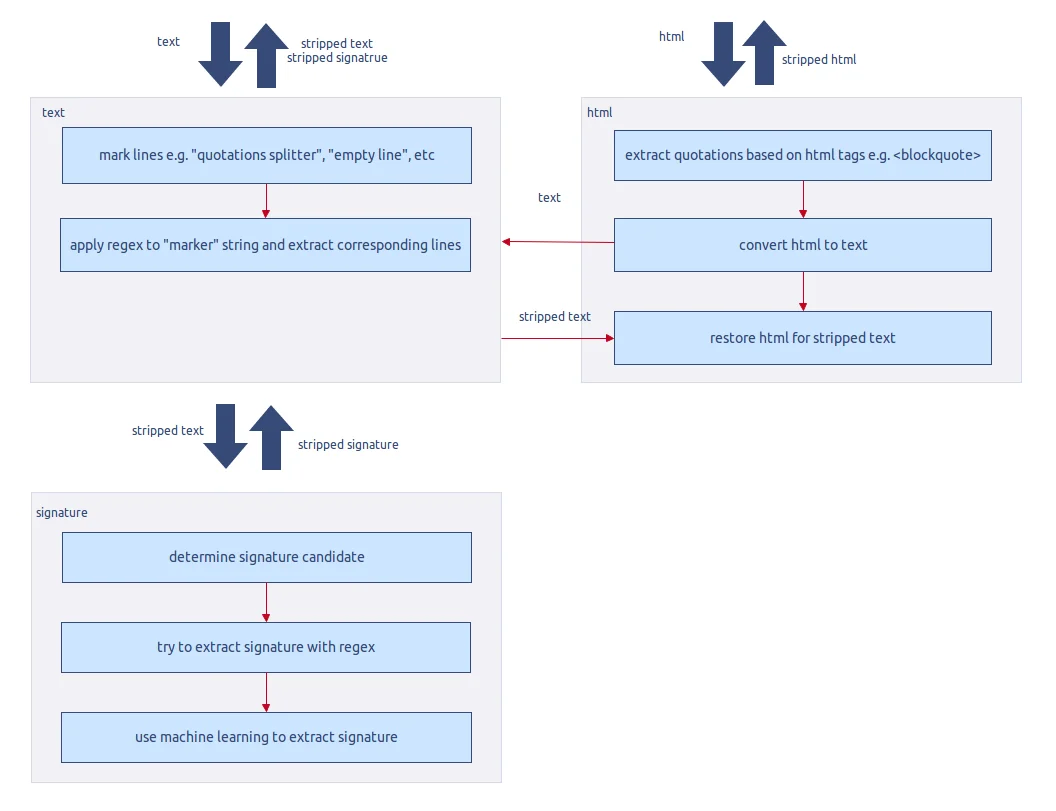
Currently, we use machine learning only to classify signature lines. The rest of the library are various heuristics and sanity checks we came up with while working on support tickets and analyzing message formatting patterns/trends.
The machine learning part of the library is inspired by the following research papers:
- http://www.cs.cmu.edu/~vitor/papers/sigFilePaper_finalversion.pdf
- http://www.cs.cornell.edu/people/tj/publications/joachims_01a.pdf
To classify signature lines we used SVM with Linear Kernel. To assess our classifiers we used 5-fold cross-validation:
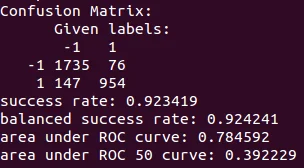
The dataset consisted of 2912 email lines. Out of 1030 signature lines 954 were classified correctly. Out of 1882 non-signature lines, 147 were mistaken for signature. Overall it gives us 92% success rate and 78% area under the ROC curve. Which could be regarded as excellent and fair correspondingly.
When we modified the library for outsourcing, we tried to provide a sturdy skeleton while making it easy to add more meat. From experience, the parts that could use the most focus are the regexps for quotations / signature separators and HTML quotations extraction by HTML tags. However, you are certainly welcome to contribute to any part of the library you like.
We hope that you’ll find the library useful and it makes your life easier.
Happy Sending!