Product
We just open sourced flanker, our Python email address and MIME parsing library
Mailgun has open sourced their address and MIME parsing library written in Python. Read more to learn about Flanker and what it can do for your sending –
Product
Back in June, we released our address validation service Guardpost. Since then many Mailgun customers have been using Guardpost to validate their email addresses and reduce their false signups as well as bounce rates. In June we promised we would open source our address and MIME parsing library written in Python and that’s what we are doing today. Read on for details, or if you want to jump right into it, here’s the repo on Github, which includes a Quickstart Guide, User Manual and API Guide. You can also install flanker via pip.
Flanker consists of two parts:
Mailgun parses a lot of MIME, and therefore requires a fast and efficient MIME handling package. When we started Mailgun, we used the standard Python parsing library, but quickly found that we needed something more predictable. Since the standard library was pretty fast for small messages, but much worse for larger messages, we wrote Flanker. Where flanker really shines is header parsing. Flanker doesn’t parse the entire message if you are only interested in the headers, this gives you fast access to headers if your MIME message is 1 KB or 10 MB. Depending on the MIME message being processed, flanker.mime can be up to 20x faster than the standard Python MIME parsing package, use ~50% less memory, and make up to 730x fewer function calls. You can view all of the benchmarks we ran here.
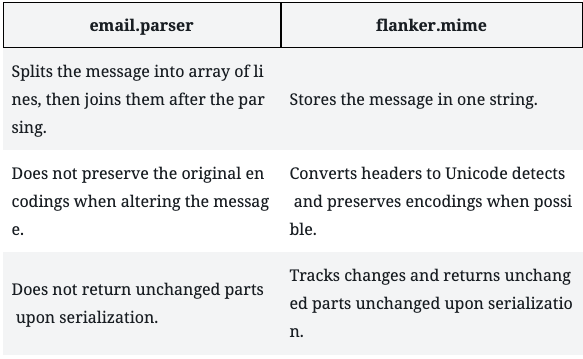
What else is different about flanker.mime from email.parser?
Parsing in addresslib is a really powerful feature, and you can dig into the docs to see everything you can do. Another really cool feature of addresslib is the validate function. This is a major part of our email verification service.
Validation includes the parsing steps outlined in the docs, plus:
Once an address is parsed, the validator attempts a DNS lookup on the domain. MX records are checked first, if they don’t exist, the validator will fall back to A records. If neither MX or A records exist, the address is considered invalid. By default, flanker uses the dnsq library (also written by Mailgun) to perform DNS lookups, however, use of dnsq is not required. Any DNS lookup library can be used as long as it conforms to the same interface as that of a Python dictionary. See flanker/addresslib/drivers/dns_lookup.py for an example.
If the DNS lookup in the previous step returned a valid MX or A record, that address is checked to ensure that a Mail Exchanger responds on port 25. If no Mail Exchanger responds, the domain is considered invalid. DNS Lookup and MX existence checks are expensive, and the result of the above two steps can be cached to improve performance. Flanker, by default, uses Redis for this cache, but use of Redis is not required. Similar to the DNS lookup library, any cache can be used here, as long as the interface is the same as that of a Python dictionary. See flanker/addresslib/drivers/redis_cache.py for an example.
Large ESPs rarely, if ever, support the full grammar that the RFC allows for email addresses, in fact, most have a fairly restrictive grammar. For example, a Yahoo! Mail address must be between 4-32 characters and can only use alphanum, dot (.) and underscore (_). If the mail exchanger in the previous step matches the mail exchanger for an ESP, with known grammar, then the validator will run that additional check on the local part of the address. Custom grammar can be added by adding a plugin for the specific ESP to the flanker/addresslib/plugins directory. See the User Manual for more information.
A separate, though related step, is spelling correction on the domain portion of an email address. This can be used to correct common typos like gmal.com instead of gmail.com. The spelling corrector uses difflib, which uses the Ratcliff-Obershelp algorithm to compute the similarity of two strings. This is a very fast and accurate algorithm for domain spelling correction. See our previous post about this topic.
You can fork flanker and start using it today. We are super excited about the community both using it and contributing to it. Flanker, being an integral part of Mailgun, means we will be actively maintaining it and improving it as long as we’re around.
We really want to encourage new developers to contribute to Flanker and open source software in general. Here are two things on our roadmap that are low hanging fruit that a new developer can jump in and start contributing:
Happy sending!
The Mailgunners

