Product
How and why we adopted service mesh with Vulcand and Nginx
Over the past year, service mesh has officially become a thing, thanks to the launch of Istio (a joint collaboration between IBM, Google, and Lyft) and the adoption of linkerd by big companies like PayPal and Ticketmaster.
So what is a service mesh, why have we adopted it at Mailgun, and how are we using it to deliver our software?

What Is a Service Mesh and Why Use It?
In simple terms, a service mesh is a bit of software (usually a proxy) that handles service-to-service communication in a fast and resilient manner. Say I’m an HTTP-based user service, and I want to contact the account service to verify a user. In a typical non-mesh architecture, the user service would make a request to
In a service mesh, the user service makes an HTTP request to
The major advantage to service mesh is that it allows for high resiliency (no load balancer single point of failure), built-in service discovery, and zero downtime releases. Most modern service-mesh implementations provide many more features, but these factors were the major motivation in our adoption of a service-mesh architecture.
Where Vulcand Comes In
Back in 2014, no one had even heard of a service mesh. When we started vulcand, we wanted to build a high-performance reverse proxy that would provide some smart request throttling and allow us to dynamically add and remove backend services on the fly, thus enabling zero downtime deployments. We definitely didn’t set out to build a service-mesh router.
But soon after, we started wondering what would happen if, instead of running vulcand as a traditional front-end load balancer, we had all our services talk to each other via the local vulcand instance.

We quickly realized how much freedom this would provide. Using vulcand this way would avoid additional load balancers, provide zero downtime releases, increase resiliency, and facilitate service discovery. We had inadvertently created what the industry would eventually call a service-mesh.
How Mailgun Manages Service Mesh Routes
There are two schools of thought for managing service-mesh routes. A central governance model and the distributed ungoverned model.
In a central governance model, route configuration is stored and managed centrally, usually by a company-appointed architect whose job is to ensure the consistency of API routes, resolve route conflicts across the entire service mesh, set weights, and route destinations.
With the distributed model, each service owner determines what routes its service provides, often using a route prefix to avoid conflicts (i.e. ‘/service-1/users’ would not conflict with ‘/service-2/users’).
At Mailgun, we’ve adopted the distributed ungoverned model so each service is responsible for informing vulcand about the routes the service provides. Services do this by registering their routes with vulcand via etcd during service startup. If my service handles requests for ‘/users,’ it would register this route with vulcand. With this route configured, requests made to the local vulcand instance,
We feel like the distributed model allows us to deliver and experiment much more rapidly than if we had embraced a central governance model. By distributing ownership of the route configuration to each service, we lower the barrier of adding new capabilities to services and bypass the additional configuration step before testing and deployment.
Because vulcand stores its configuration in [etcd, it’s simple for services to add and update new routes. To lower the barrier even further, we have libraries in go and python that make publishing routes to etcd easy. Anyone with read access to etcd can inspect what routes belong to a service, which can help avoid route conflicts. Even so, route conflicts can happen, but it’s very rare and usually caught early in testing.
The ungoverned model provides our developers with great power and flexibility, but if uncontrolled, it could give external users unintended access to routes and functionality we don’t want to expose. To control which routes and services external users can access, we use an additional proxy layer so only the appropriate service routes are exposed.
Exposing Service Mesh As A Public API
We use [nginx](https://nginx.org/) to expose specific routes within our service mesh for public consumption. The resulting architecture looks something like this:
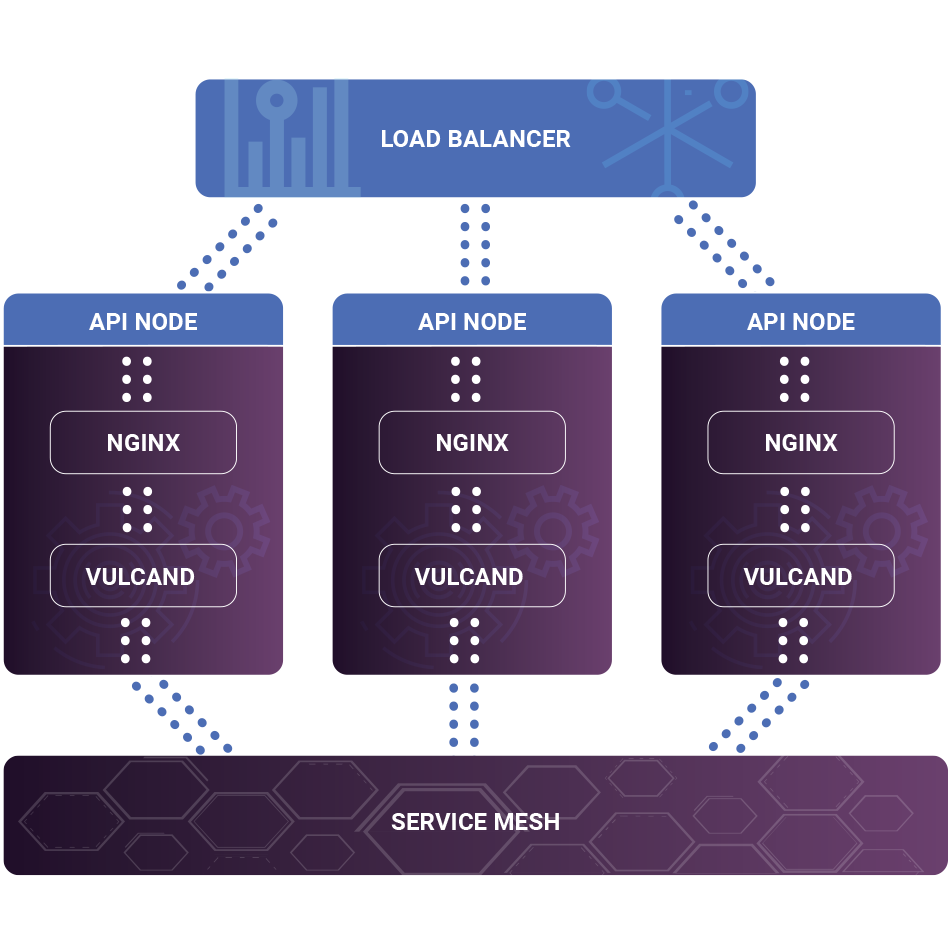
On the front end, we load balance a pool of nginx workers that proxy specific requests to our service mesh via locally running vulcand instances. Running vulcand locally on each nginx node allows the node to become a member of the service mesh. This lets us avoid a single point of failure if one nginx node fails.
Within our nginx configuration, we add location directives for the specific service mesh routes we wish to expose. For instance, the following directive accepts routes that begin with ‘/users’ and forwards them to vulcand to be routed to the appropriate service.
location ~ ^/users/($|/.*$) {rn limit_req zone=api burst=280 nodelay;rn}rnupstream vulcand {rn server localhost:9003 fail_timeout=30s;rn }
If an internal service uses a path prefix model, we could have nginx rewrite requests to target specific services by prefix. For example, requests to ‘/users’ could be re-written to ‘/user-service/users’ within the service mesh so that the user-service would respond to that request.
Using nginx in this manner gives us something of a DMZ for external requests before they enter the service mesh. This insulates us from insecure HTTP requests and limits customer access to our service mesh.
Conclusion
The service-mesh model allows us to build small teams of developers focused on delivering high-performance products to our customers quickly and reliably. Leveraging an nginx proxy layer gives us the tools needed to control and scale our services to meet the needs of our customers.
Interested in working at Mailgun? We’re hiring! And there are several dev positions available. Check out our current openings here!